This next-generation architecture for VMware Cloud on AWS enabled by an Amazon EC2 M7i bare-metal diskless instance featuring a custom 4th Gen Intel Xeon processor is really bringing a lot of value to our customers. As they combined this instance with scalable and flexible storage options, it […]
For Private AI in HomeLAB, I was searching for budget-friendly GPUs with a minimum of 24GB RAM. Recently, I came across the refurbished NVIDIA Tesla P40 on eBay, which boasts some intriguing specifications:
GPU Chip: GP102
Cores: 3840
TMUs: 240
ROPs: 96
Memory Size: 24 GB
Memory Type: GDDR5
Bus Width: 384 bit
Since the NVIDIA Tesla P40 comes in a full-profile form factor, we needed to acquire a PCIe riser card.
A PCIe riser card, commonly known as a “riser card,” is a hardware component essential in computer systems for facilitating the connection of expansion cards to the motherboard. Its primary role comes into play when space limitations or specific orientation requirements prevent the direct installation of expansion cards into the PCIe slots on the motherboard.
Furthermore, I needed to ensure adequate cooling, but this posed no issue. I utilized a 3D model created by MiHu_Works for a Tesla P100 blower fan adapter, which you can find at this link: Tesla P100 Blower Fan Adapter.
As for the fan, the Titan TFD-B7530M12C served the purpose effectively. You can find it on Amazon: Titan TFD-B7530M12C.
Currently, I am using a single VM with PCIe pass-through. However, it was necessary to implement specific Advanced VM parameters:
pciPassthru.use64bitMMIO = true
pciPassthru.64bitMMIOSizeGB = 64
Now, you might wonder about the performance. It’s outstanding, delivering speeds up to 16x-26x times faster than the CPU. To provide you with an idea of the performance, I conducted a llama-bench test:
For my project involving the AI tool llama.cpp, I needed to free up a PCI slot for an NVIDIA Tesla P40 GPU. I found an excellent guide and a useful video from ArtOfServer.
Based on this helpful video from ArtOfServer:
ArtOfServer wrote a small tutorial on how to modify an H200A (external) into an H200I (internal) to be used into the dedicated slot (e.g. instead of a Perc6i)
ArtOfServer wrote a small tutorial on how to modify an H200A (external) into an H200I (internal) to be used into the dedicated slot (e.g. instead of a Perc6i)
Install compiler and build tools (those can be removed later)
# apt install build-essential unzip
Compile and install lsirec and lsitool
# mkdir lsi
# cd lsi
# wget https://github.com/marcan/lsirec/archive/master.zip
# wget https://github.com/exactassembly/meta-xa-stm/raw/master/recipes-support/lsiutil/files/lsiutil-1.72.tar.gz
# tar -zxvvf lsiutil-1.72.tar.gz
# unzip master.zip
# cd lsirec-master
# make
# chmod +x sbrtool.py
# cp -p lsirec /usr/bin/
# cp -p sbrtool.py /usr/bin/
# cd ../lsiutil
# make -f Makefile_Linux
# lsirec 0000:05:00.0 unbind
Trying unlock in MPT mode...
Device in MPT mode
Kernel driver unbound from device
# lsirec 0000:05:00.0 halt
Device in MPT mode
Resetting adapter in HCB mode...
Trying unlock in MPT mode...
Device in MPT mode
IOC is RESET
Read sbr:
# lsirec 0000:05:00.0 readsbr h200.sbr
Device in MPT mode
Using I2C address 0x54
Using EEPROM type 1
Reading SBR...
SBR saved to h200.sbr
Transform binary sbr to text file:
# sbrtool.py parse h200.sbr h200.cfg
Modify PID in line 9 (e.g using vi or vim):
from this:
SubsysPID = 0x1f1c
to this:
SubsysPID = 0x1f1e
Important: if in the cfg file you find a line with:
SASAddr = 0xfffffffffffff
remove it!
Save and close file.
Build new sbr file:
# sbrtool.py build h200.cfg h200-int.sbr
Write it back to card:
# lsirec 0000:05:00.0 writesbr h200-int.sbr
Device in MPT mode
Using I2C address 0x54
Using EEPROM type 1
Writing SBR...
SBR written from h200-int.sbr
Reset the card an rescan the bus:
# lsirec 0000:05:00.0 reset
Device in MPT mode
Resetting adapter...
IOC is RESET
IOC is READY
# lsirec 0000:05:00.0 info
Trying unlock in MPT mode...
Device in MPT mode
Registers:
DOORBELL: 0x10000000
DIAG: 0x000000b0
DCR_I2C_SELECT: 0x80030a0c
DCR_SBR_SELECT: 0x2100001b
CHIP_I2C_PINS: 0x00000003
IOC is READY
# lsirec 0000:05:00.0 rescan
Device in MPT mode
Removing PCI device...
Rescanning PCI bus...
PCI bus rescan complete.
Hard to believe VMware Explore Barcelona just concluded a couple of days ago! Hats off to the VMware Explore production team who have already published a large majority of the breakout session recordings including the presentation PDF! On Friday, I had shared an update and out of […]
Support for Single Root I/O Virtualization (SR-IOV) was first introduced back in 2012 with the release of vSphere 5.1 and enables for a physical PCIe device to be shared amongst a number of Virtual Machines. The networking industry was the first to take advantage of the SR-IOV technology […]
There have been some recent reports from users observing performance issues when running VMware Workstation on Windows 11 along with using recent Intel (12th Gen and later) Hybrid CPUs, which introduces a new hybrid big.LITTLE architecture for Intel’s x86 consumer CPUs. This new Intel Hybrid CPU […]
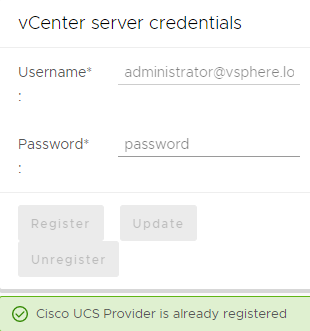
Cisco UCS / Proactive HA Registration / vCenter server credentials / Register
Cisco UCS / Proactive HA Registration / Register
How Could I check it? Edit Proactive HA / Providers
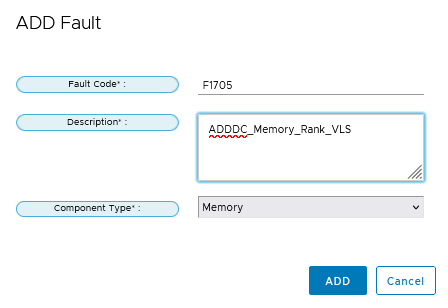
It is better use Name “ADDDC_Memory_Rank_VLS” without spaces. On my picture I used “My F1705 Alerts”
Adding Custom Alert is only possible with unregistered Cisco UCS Provider, it is better to do it immediatly after Cisco UCS Manager Plugin instalation.
Now I can deceided If I will block F1705 or NOT. I personaly preffer to have F1705 Alert under Proactive HA. Then I only restart Blades with F1705. During reboot Hard-PPRpermanently remaps accesses from a designated faulty row to a designated spare row.
Often, Kubernetes and cloud native applications are a strange world to traditional network and security teams. However, any legacy or modern app needs […]
This white paper leverages VMware Private AI for GenAI workloads; serves as an essential guide, providing insights into the architecture design, implementation, and best practices for LLM fine-tuning and inference.