How to design NSX-T Edge inside Cisco UCS? I can’t find it inside Cisco Design Guide. But I find usefull topology inside Dell EMC VxBlock™ Systems, VMware® NSX-T Reference Design and NSX-T 3.0 Edge Design Step-by-Step UI workflow. Thanks DELL and VMware …
VMware® NSX-T Reference Design
- VDS Design update – New capability of deploying NSX on top of VDS with NSX
- VSAN Baseline Recommendation for Management and Edge Components
- VRF Based Routing and other enhancements
- Updated security functionality
- Design changes that goes with VDS with NSX
- Performance updates
NSX-T 3.0 Edge Design Step-by-Step UI workflow
This document is an informal document that walks through the step-by-step deployment and configuration workflow for NSX-T Edge Single N-VDS Multi-TEP design. This document uses NSX-T 3.0 UI to show the workflow, which is broken down into following 3 sub-workflows:
- Deploy and configure the Edge node (VM & BM) with Single-NVDS Multi-TEP.
- Preparing NSX-T for Layer 2 External (North-South) connectivity.
- Preparing NSX-T for Layer 3 External (North-South) connectivity.
NSX-T Design with EDGE VM
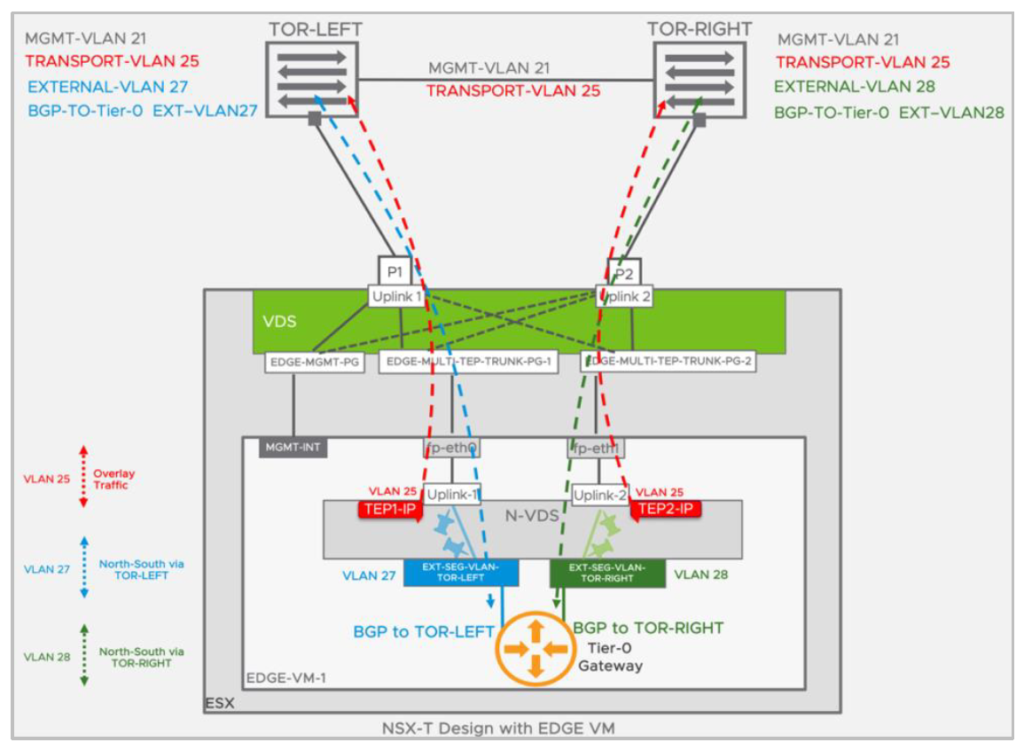
- Under Teamings – Add 2 Teaming Policies: one with Active Uplink as “uplink-1” and other with “uplink-2”.
- Make a note of the policy name used, as we would be using this in the next section. In this example they are “PIN-TO-TOR-LEFT” and “PIN-TO-TOR-RIGHT”.
How to design NSX-T Edge inside Cisco UCS?
Cisco Fabric Interconnect using Port Chanel. You need high bandwith for NSX-T Edge load.
C220 M5 could solved it.
The edge node physical NIC definition includes the following
- VMNIC0 and VMNIC1: Cisco VIC 1457
- VMNIC2 and VMNIC3: Intel XXV710 adapter 1 (TEP and Overlay)
- VMNIC4 and VMNIC4: Intel XXV710 adapter 2 (N/S BGP Peering)
NSX-T transport nodes![]() with Cisco UCS C220 M5
with Cisco UCS C220 M5
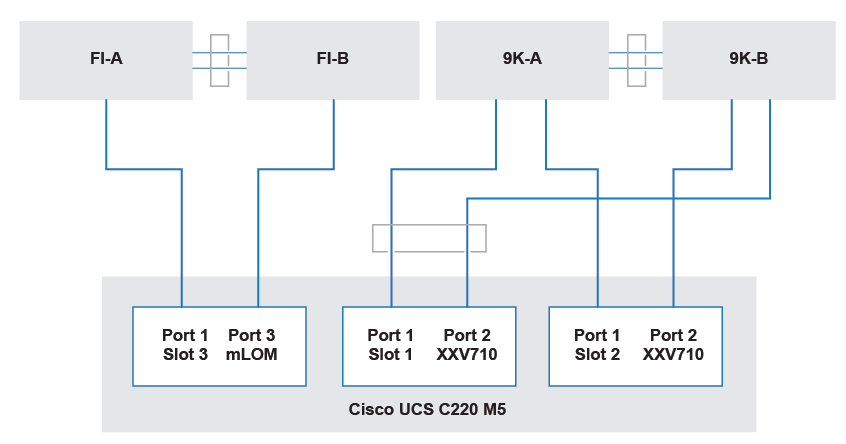
Logical topology of the physical edge host

Or for PoC or Lab – Uplink Eth Interfaces
For PoC od HomeLAB We could use Uplink Eth Interfaces and create vNIC template linked to these uplink.




{kind=link}