Welcome to the exciting world of Llama-2 models! In today’s blog post, we’re diving into the process of installing and running these advanced models. Whether you’re a seasoned AI enthusiast or just starting out, understanding Llama-2 models is crucial. These models, known for their efficiency and versatility in handling large-scale data, are a game-changer in the field of machine learning.
In this Shortcut, I give you a step-by-step process to install and run Llama-2 models on your local machine with or without GPUs by using llama.cpp. As I mention in Run Llama-2 Models, this is one of the preferred options.
Here are the steps:
Step 1. Clone the repositories
You should clone the Meta Llama-2 repository as well as llama.cpp:
$ git clone https://github.com/facebookresearch/llama.git
$ git clone https://github.com/ggerganov/llama.cpp.git Step 2. Request access to download Llama models
Complete the request form, then navigate to the directory where you downloaded the GitHub code provided by Meta. Run the download script, enter the key you received, and adhere to the given instructions:
$ cd llama
$ ./download Step 3. Create a virtual environment
To prevent any compatibility issues, it’s advisable to establish a separate Python environment using Conda. In case Conda isn’t already installed on your system, you can refer to this installation guide. Once Conda is set up, you can create a new environment by entering the command below:
#https://docs.conda.io/projects/miniconda/en/latest/
#These four commands quickly and quietly install the latest 64-bit version #of the installer and then clean up after themselves. To install a different #version or architecture of Miniconda for Linux, change the name of the .sh #installer in the wget command.
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
#After installing, initialize your newly-installed Miniconda. The following #commands initialize for bash and zsh shells:
~/miniconda3/bin/conda init bash
~/miniconda3/bin/conda init zsh$ conda create -n llamacpp python=3.11Step 4. Activate the environment
Use this command to activate the environment:
$ conda activate llamacppStep 5. Go to llama.cpp folder and Install the required dependencies
Type the following commands to continue the installation:
$ cd ..
$ cd llama.cpp
$ python3 -m pip install -r requirements.txtStep 6.
Compile the source code
Option 1:
Enter this command to compile with only CPU support:
$ make Option 2:
To compile with CPU and GPU support, you need to have the official CUDA libraries from Nvidia installed.
#https://developer.nvidia.com/cuda-12-3-0-download-archive?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=22.04&target_type=deb_local
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.3.0/local_installers/cuda-repo-ubuntu2204-12-3-local_12.3.0-545.23.06-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2204-12-3-local_12.3.0-545.23.06-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2204-12-3-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-3
sudo apt-get install -y cuda-driversDouble check that you have Nvidia installed by running:
$ nvcc --version
$ nvidia-smiExport the the CUDA Home environment variable:
$ export CUDA_HOME=/usr/lib/cudaThen, you can launch the compilation by typing:
$ make clean && LLAMA_CUBLAS=1 CUDA_DOCKER_ARCH=all make -jStep 7. Perform a model conversion
Run the following command to convert the original models to f16 format (please note in the example I show examples the 7b-chat model / 13b-chat model / 70b-chat model):
$ mkdir models/7B
$ python3 convert.py --outfile models/7B/ggml-model-f16.gguf --outtype f16 ../llama/llama-2-7b-chat --vocab-dir ../llama/llama
$ mkdir models/13B
$ python3 convert.py --outfile models/13B/ggml-model-f16.gguf --outtype f16 ../llama/llama-2-13b-chat --vocab-dir ../llama/llama
$ mkdir models/70B
$ python3 convert.py --outfile models/70B/ggml-model-f16.gguf --outtype f16 ../llama/llama-2-70b-chat --vocab-dir ../llama/llama
If the conversion runs successfully, you should have the converted model stored in models/* folders. You can double check this with the ls command:
$ ls models/7B/
$ ls models/13B/
$ ls models/70B/ Step 8. Quantize
Now, you can quantize the model to 4-bits, for example, by using the following command (please note the q4_0 parameter at the end):
$ ./quantize models/7B/ggml-model-f16.gguf models/7B/ggml-model-q4_0.gguf q4_0
$ ./quantize models/13B/ggml-model-f16.gguf models/13B/ggml-model-q4_0.gguf q4_0
$ ./quantize models/70B/ggml-model-f16.gguf models/70B/ggml-model-q4_0.gguf q4_0
$ ./quantize models/70B/ggml-model-f16.gguf models/70B/ggml-model-q2_0.gguf Q2_K$ ./quantize -h
usage: ./quantize [--help] [--allow-requantize] [--leave-output-tensor] [--pure] model-f32.gguf [model-quant.gguf] type [nthreads]
--allow-requantize: Allows requantizing tensors that have already been quantized. Warning: This can severely reduce quality compared to quantizing from 16bit or 32bit
--leave-output-tensor: Will leave output.weight un(re)quantized. Increases model size but may also increase quality, especially when requantizing
--pure: Disable k-quant mixtures and quantize all tensors to the same type
Allowed quantization types:
2 or Q4_0 : 3.56G, +0.2166 ppl @ LLaMA-v1-7B
3 or Q4_1 : 3.90G, +0.1585 ppl @ LLaMA-v1-7B
8 or Q5_0 : 4.33G, +0.0683 ppl @ LLaMA-v1-7B
9 or Q5_1 : 4.70G, +0.0349 ppl @ LLaMA-v1-7B
10 or Q2_K : 2.63G, +0.6717 ppl @ LLaMA-v1-7B
12 or Q3_K : alias for Q3_K_M
11 or Q3_K_S : 2.75G, +0.5551 ppl @ LLaMA-v1-7B
12 or Q3_K_M : 3.07G, +0.2496 ppl @ LLaMA-v1-7B
13 or Q3_K_L : 3.35G, +0.1764 ppl @ LLaMA-v1-7B
15 or Q4_K : alias for Q4_K_M
14 or Q4_K_S : 3.59G, +0.0992 ppl @ LLaMA-v1-7B
15 or Q4_K_M : 3.80G, +0.0532 ppl @ LLaMA-v1-7B
17 or Q5_K : alias for Q5_K_M
16 or Q5_K_S : 4.33G, +0.0400 ppl @ LLaMA-v1-7B
17 or Q5_K_M : 4.45G, +0.0122 ppl @ LLaMA-v1-7B
18 or Q6_K : 5.15G, -0.0008 ppl @ LLaMA-v1-7B
7 or Q8_0 : 6.70G, +0.0004 ppl @ LLaMA-v1-7B
1 or F16 : 13.00G @ 7B
0 or F32 : 26.00G @ 7B
COPY : only copy tensors, no quantizingStep 9. Run one of the prompts
Option 1:
You can execute one of the example prompts using only CPU computation by typing the following command:
$ ./main -m ./models/7B/ggml-model-q4_0.gguf -n 1024 --repeat_penalty 1.0 --color -i -r "User:" -f ./prompts/chat-with-bob.txtThis example will initiate the chat in interactive mode in the console, starting with the chat-with-bob.txt prompt example.
Option 2:
If you compiled llama.cpp with GPU enabled in Step 8, then you can use the following command:
$ ./main -m ./models/7B/ggml-model-q4_0.gguf -n 1024 --repeat_penalty 1.0 --color -i -r "User:" -f ./prompts/chat-with-bob.txt --n-gpu-layers 3800
$ ./main -m ./models/13B/ggml-model-q4_0.gguf -n 1024 --repeat_penalty 1.0 --color -i -r "User:" -f ./prompts/chat-with-bob.txt --n-gpu-layers 3800
$ ./main -m ./models/70B/ggml-model-q4_0.gguf -n 1024 --repeat_penalty 1.0 --color -i -r "User:" -f ./prompts/chat-with-bob.txt --n-gpu-layers 1000If you have GPU enabled, you need to set the number of layers to offload to the GPU based on your vRAM capacity. You can increase the number gradually and check with the nvtop command until you find a good spot.
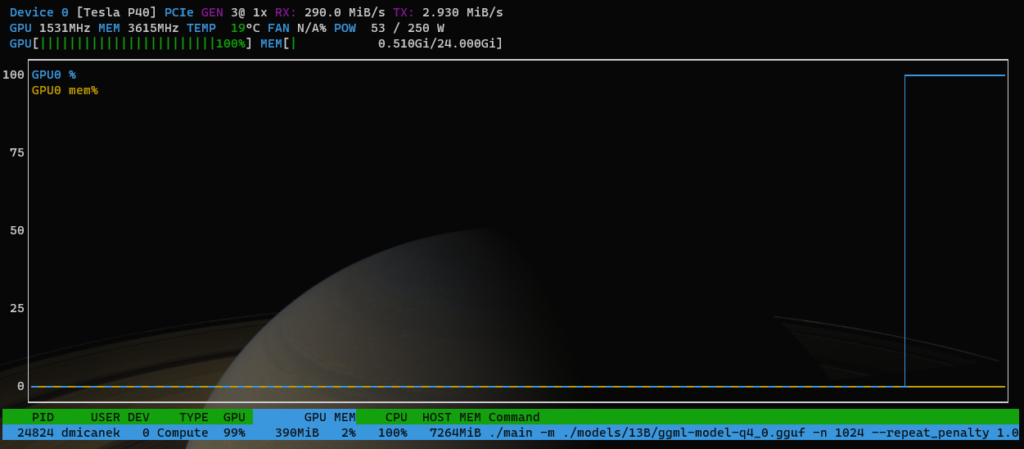
You can see the full list of parameters of the main command by typing the following:
$ ./main --help