I am thrilled to share my experience with the latest UCSM-plugin 4.0 for VMware vSphere 8U2, a remarkable tool that has significantly enhanced our virtualization management capabilities. Having tested its functionality across an extensive network of approximately 13 UCSM domains and 411 ESXi 8U2 hosts. A notable instance of its efficacy was observed with Alert F1236, where the Proactive HA feature seamlessly transitioned the Blade into Quarantine mode, showcasing the plugin’s advanced automation capabilities.
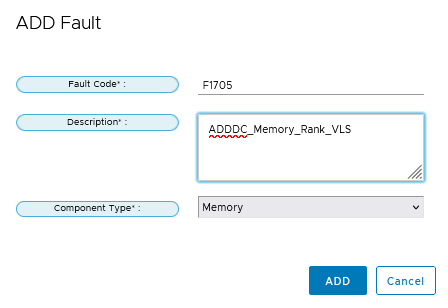
However, I did encounter a challenge with the configuration of Custom Alerts, particularly Alert F1705. Despite my efforts, Proactive HA failed to activate, suggesting a potential misconfiguration on my part. To streamline this process, I propose the integration of Alert F1705 into the default alert settings, thereby simplifying the setup and ensuring more efficient system monitoring.
The release of Cisco’s 4.0(0) version of the UCS Manager VMware vSphere 8U2 HTML remote client plugin marks a significant advancement in the field of virtualization administration. This plugin not only offers a comprehensive physical view of the UCS hardware inventory through the HTML client but also enhances the overall management and monitoring of the Cisco UCS physical infrastructure.
Key functionalities provided by this plugin include:
- Detailed Physical Hierarchy View: Gain a clear understanding of the Cisco UCS physical structure.
- Comprehensive Inventory Insights: Access detailed information on inventory, installed firmware, faults, and power and temperature statistics.
- Physical Server to ESXi Host Mapping: Easily correlate your ESXi hosts with their corresponding physical servers.
- Firmware Management: Efficiently manage firmware for both B and C series servers.
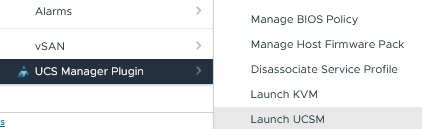
- Direct Access to Cisco UCS Manager GUI: Launch the Cisco UCS Manager GUI directly from the plugin.
- KVM Console Integration: Instantly launch KVM consoles of UCS servers for immediate access and control.
- Locator LED Control: Switch the state of the locator LEDs as needed for enhanced hardware identification.
- Proactive HA Fault Configuration: Customize and configure faults used in Proactive HA for improved system resilience.

Links
Please see the User Guide for specific information on installing and using the plugin with the vSphere HTML client.






{kind=link}