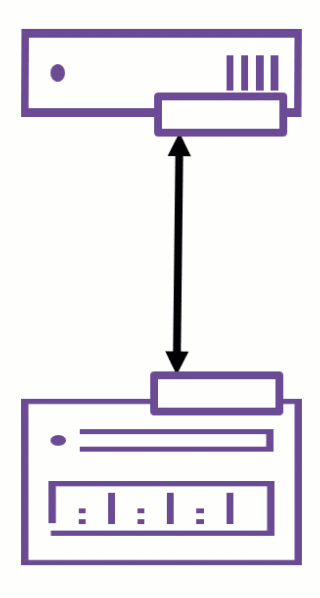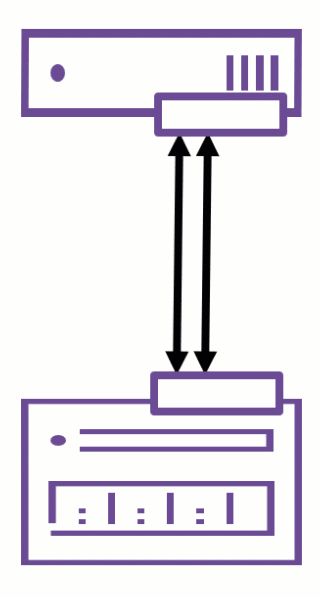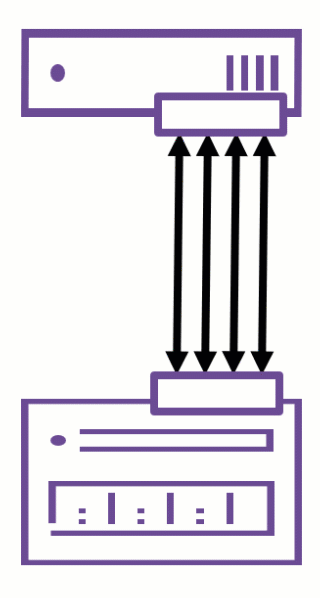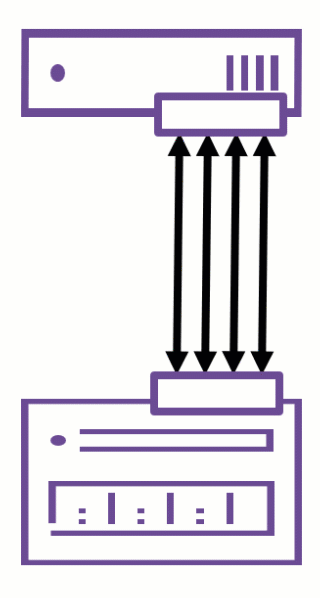
With the release of VMware ESXi 8.0 Update 1, VMware quietly introduced nConnect support in the NFS client — a long-awaited enhancement for environments using NFSv3 datastores.
The nConnect feature allows administrators to establish multiple parallel TCP connections per NFS datastore, significantly improving throughput, resiliency, and traffic isolation.
This guide walks you through how to configure nConnect, supported versions, and key operational tips.
🆕 What’s New in ESXi 8.0U1
From ESXi 8.0U1 onwards, a new parameter -c (number of connections) is available in esxcli when mounting NFSv3 datastores.
esxcli storage nfs add \
-H <host> \
-v <volume-label> \
-s <remote_share> \
-c <number_of_connections>Key points:
- Supported for NFSv3 only (NFSv4.1 not yet supported).
- Currently available only via CLI, not via vCenter UI.
- Host Profiles don’t officially support it yet (though there’s a workaround, see below).
- Default max connections per datastore: 4
- Adjustable up to 8 connections via advanced option:
esxcfg-advcfg -s 8 /NFS/MaxConnectionsPerDatastore
⚠️ The total number of connections across all mounted NFSv3 datastores is capped at 256.
Runtime Scaling in ESXi 8.0U2
The nConnect feature got a useful upgrade in VMware ESXi 8.0 Update 2.
You can now increase or decrease the number of TCP connections on an existing NFSv3 mount without unmounting the datastore:
esxcli storage nfs param set \
-v <volume-label> \
-c <number_of_connections>This flexibility helps admins fine-tune NFS performance on the fly — for example, ramping up connections during heavy backup windows or scaling down during low I/O periods.
Note: In both 8.0U1 and 8.0U2, the default number of connections remains
1.
How to Check Active NFS Connections
To view the number of RPC clients currently used by mounted NFSv3 datastores, run:
vsish -e get /vmkModules/nfsclient/infoSample output:
NFS Connections Info {
mountedVolumes:10
totalConnections 40
}This command is particularly handy for performance troubleshooting and capacity planning.
🧪 Experimental: Host Profile Integration
Although official Host Profile support for nConnect is not yet released, VMware added an experimental field named “Number of TCP connections” in:
Host Profile → Storage Configuration → NFS
What it does:
When you set a value here, ESXi will use that number of parallel TCP sessions when mounting the NFS datastore during profile remediation.
This is ideal for consistent deployment across multiple hosts in larger clusters.
Best Practices & Tips
- Start with 4 connections and scale up as needed after performance testing.
- Keep the 256 connection limit in mind when mounting multiple datastores.
- Use consistent configuration across hosts to avoid mount mismatches.
- Monitor performance metrics via VMware vSphere or CLI.
- If you’re using Host Profiles, experiment carefully with the TCP connection parameter.
Summary
The nConnect feature in ESXi’s NFS client marks a major step forward in improving NFSv3 performance and scalability in enterprise environments.
Whether you’re running backup workloads, large VMs, or latency-sensitive applications, multiple TCP connections per NFS datastore can make a measurable difference.
If you’re upgrading to VMware ESXi 8.0U1 or later, nConnect is worth testing and adopting in your storage strategy.