Daniel Micanek virtual Blog – Like normal Dan, but virtual.
Category: AI
Welcome to the AI category of my blog, where we delve into the rapidly evolving world of Artificial Intelligence. Here, I explore the latest AI trends, breakthroughs, and applications shaping our future. Whether you’re a tech enthusiast, a seasoned developer, or simply curious about AI, our posts aim to enlighten and inspire.
Are you looking to maximize AI/ML performance in your virtualized environment? At VMware Explore 2025, I attended a compelling session — INVB1158LV: Accelerating AI Workloads: Mastering vGPU Management in VMware Environments — that unpacked how to effectively configure and scale GPUs for AI workloads in vSphere.
This blog post shares key takeaways from the session and outlines how to use vGPU, MIG, and Passthrough to achieve optimal performance for AI inference and training on VMware Cloud Foundation 9.0.
vGPU Configuration Options in VMware vSphere
🔹 1. DirectPath I/O (Passthrough)
A dedicated GPU is assigned to a single VM or containerized workload.
Ideal for maximum performance and full GPU access (e.g., LLM training).
No sharing or resource fragmentation.
🔹 2. NVIDIA vGPU – Time Slicing Mode
Shares one physical GPU across multiple VMs.
Each VM gets 100% of GPU cores for a slice of time, while memory is statically partitioned.
Supported on all NVIDIA GPUs.
Useful for efficient GPU sharing, especially for model inference and dev/test setups.
✅ Example profiles: grid_a100-8c, grid_a100-4-20c
🔹 3. Multi-Instance GPU (MIG)
Available on NVIDIA Ampere & Hopper (e.g., A100, H100).
Splits GPU into isolated hardware slices (compute + memory).
Offers deterministic performance and better isolation.
Best for multi-tenant AI inference, production-grade deployments.
✅ Example profiles: MIG 1g.5gb, MIG 2g.10gb, MIG 3g.20gb ✅ Assignable via vSphere UI with profiles like grid_a100-3-20c
Time Slicing vs. MIG – When to Use What?
Mode
Best For
Sharing Type
Time Slicing
LLM training, dev/test environments
Time-shared
MIG
Production inference, multitenancy
Spatial (hardware)
Passthrough
Maximum performance for single workload
Not shared
Smarter vMotion for AI Workloads in VCF 9.0
One of the standout improvements presented during session INVB1158LV was the vMotion optimization for VMs using vGPUs. With vSphere 8.0 U3 and VMware Cloud Foundation 9.0, the way vMotion handles GPU memory has been completely reengineered to minimize downtime (stun time) during live migration.
Instead of migrating all GPU memory during the VM stun phase, 70% of the vGPU cold data is now pre-copied in the pre-copy stage, and only the final 30% is checkpointed during stun. This greatly accelerates live migration even for massive LLM workloads running on multi-GPU systems.
📊 Example results with Llama 3.1 models:
Migrating a VM using 2×H100 GPUs (144 GB vGPU memory) saw stun time drop from 24.5s to just 6.3s.
Migrating a large model on 8×H100 (576 GB) now completes in 21s, compared to 325s for a power-off-and-reload approach — that’s a 15× improvement.
These enhancements make zero-downtime AI infrastructure upgrades and scaling possible, even for large language model deployments
At today’s VMware Explore general session, Chris Wolf showcased Intelligent Assist for VMware Cloud Foundation — bringing AI-powered assistance directly to our users.
Today at VMware Explore’s general session you saw Chris Wolf demonstrate Intelligent Assist for VMware Cloud Foundation, providing AI-powered assistance for our users. In this blog, we’ll take a step behind the curtain to see how these capabilities are running in VCF, using AI features that […]
Today at hashtag#VMwareExplore, Broadcom and AMD announced an expanded collaboration to deliver private, secure, and high-performance AI infrastructure for enterprises.
Artificial Intelligence (AI) is rapidly transforming industries, and Generative AI (Gen AI) is pushing the boundaries of what’s possible, creating new content and redefining value creation. However, enterprises face significant challenges in AI adoption, especially concerning privacy, data […]
VMware Private AI Services Now Included in VCF Subscription Big news from today’s VMware Explore general session with Chris Wolf 🎉 What was once sold separately is now part of the platform — VCF Private AI Services are now included in your VMware Cloud Foundation subscription.
This marks a major step forward in unleashing the power of Private AI, fueled by Broadcom and NVIDIA innovations.
Enterprises can get tremendous productivity and business transformation from AI. With VMware Private AI Foundation with NVIDIA, Broadcom and NVIDIA aim to unlock AI and unleash productivity with lower TCO. Recently with VCF 9.0, Broadcom and NVIDIA released several features in VMware Private AI Foundation with NVIDIA to further our mission of providing private and … Continued The post Unleashing the Power of Private AI: New Innovations from Broadcom with NVIDIA appeared first on VMware Cloud…Read More
If you were at VMware Explore 2025, you might have caught our lightning talk: “Homelab Meets SAM2: Fine-Tune Like a Pro.”
In that session, I showed how the Segment Anything Model 2 (SAM2) can be adapted for interactive polyp segmentation in both images and videos. I also highlighted that SAM2 isn’t just about making your social media posts look cooler ✨ or segmenting funny-looking chickens 🐔— it also has the potential to save lives.
But like any live demo, what you saw on stage was only the tip of the iceberg. Behind the polished slides and smooth results were weeks of experimentation, GPU juggling, unexpected bugs, and plenty of “Why isn’t it learning?” moments.
This post is for those who want to dig deeper, whether you were in the room at VMware Explore or are exploring SAM2 on your own.
📝 Note: Many of the insights shared here are based on the practical experience and research from my Master’s thesis, which focused on interactive segmentation of medical video data.
SAM 2 builds on its predecessor, Segment Anything Model (SAM), which was released by Meta AI in April 2023. While SAM was a breakthrough in interactive open-world image segmentation, it was limited to single-image inputs and lacked native support for video or sequential data. SAM 2 extends this concept by introducing architectural changes that enable it to handle both images and videos, making it suitable for tasks that require temporal consistency, such as video object segmentation and tracking.
SAM 2 is an open-source foundational model for open-world segmentation, developed and released by Meta AI in August 2024. It was specifically designed to support interactive segmentation for both images and videos, making it one of the first models to handle temporal and spatial segmentation in a unified framework.
As an interactive model, SAM 2 accepts a wide range of user prompts — including positive and negative points, bounding boxes, and even segmentation masks. These prompts guide the model to focus on specific objects or regions, enabling precise segmentation in complex and dynamic scenes.
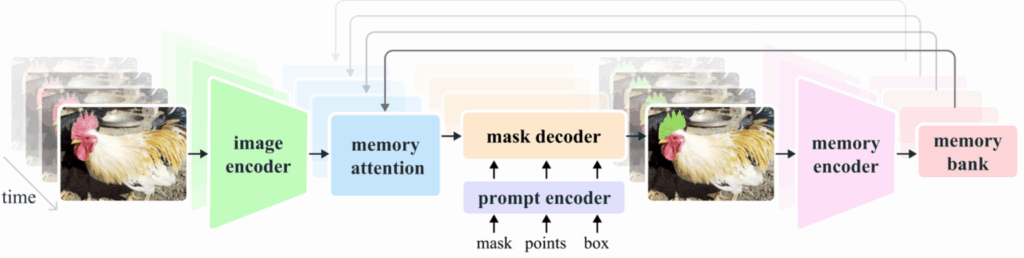
The Architecture That Powers SAM 2
SAM 2 consists of several specialized modules that work together to enable precise and temporally consistent segmentation across both images and videos. The visualization below1 provides a clear overview of how these components interact — from user prompts to final mask predictions, across time.
Image Encoder: At its core, SAM 2 uses a transformer-based encoder to extract high-level visual features from each frame. Whether it’s a single image or a sequence of video frames, this encoder captures the spatial context and object structures at each point in time.
Prompt Encoder: This module translates user-provided inputs – such as positive/negative clicks, bounding boxes, or coarse masks – into prompt embeddings. These embeddings guide the model to focus on specific objects or regions.
Memory Mechanism: To enable tracking over time, SAM 2 includes a memory system composed of a memory encoder, memory bank, and attention module. This system stores relevant features from previous frames, helping the model maintain object identity even during motion, deformation, or partial occlusion.
Mask Decoder: The decoder fuses all information – visual features, prompt embeddings, and memory context – to produce the final segmentation mask. In video mode, it leverages stored memory to ensure that objects are segmented consistently across frames
From General to Specific: Fine-Tuning SAM 2
While SAM 2 is trained on the massive and diverse SA-V dataset, making it a powerful generalist, real-world applications often require greater precision and consistency. When the model is applied to a domain that was not well-represented in the original training data — such as medical imaging or other highly specialized fields — its out-of-the-box performance may fall short.
That’s where fine-tuning comes in.
The Meta AI team provides official training and fine-tuning code for SAM 2, including detailed instructions in the training README. However, based on my experience, this codebase is quite complex and optimized for large-scale multi-GPU setups. Since I was working with a domain-specific dataset and didn’t require distributed training, I needed more granular control over the training loop and fine-tuning process. That’s why I chose to write my own simplified fine-tuning pipeline — tailored to single-GPU setups and easier to adapt to custom datasets. I’m sharing this approach here in the hope that it will be helpful for others facing similar challenges.
Fine-Tuning SAM 2 for Interactive Image Segmentation with Bounding Box Prompts
Before we begin fine-tuning, several preparation steps are required. First, we need to load the pretrained SAM 2 model. After that, we selectively enable the components we wish to fine-tune (e.g., image encoder, prompt encoder, or mask decoder). Next, we choose an appropriate loss function and optimizer based on our task and dataset. Once all components are in place, we can implement the training loop, including the forward pass and backpropagation.
For a practical introduction to how SAM 2 can be used on static images, the official SAM2 GitHub repository provides ready-to-run Jupyter notebooks. A good starting point is the image_predictor_example.ipynb, which demonstrates how to load the model, apply prompts, and generate segmentation masks.
1. Loading the Pretrained SAM 2 Model
To use Segment Anything Model 2 (SAM 2), we first need to build the model architecture and load its pretrained weights. This is done using the build_sam2 function and the SAM2ImagePredictor wrapper:
from sam2.build_sam import build_sam2
from sam2.sam2_image_predictor import SAM2ImagePredictor
sam2_checkpoint = "../checkpoints/sam2.1_hiera_small.pt"
model_cfg = "configs/sam2.1/sam2.1_hiera_s.yaml"
predictor = build_sam2(model_cfg, sam2_checkpoint, device=device)
model_cfg: Path to the YAML configuration file describing the architecture of the desired SAM 2 variant
sam2_checkpoint: Path to the corresponding pretrained model weights (.pt checkpoint).
build_sam2(...): Constructs the SAM 2 model and loads its weights.
SAM2ImagePredictor(...): Wraps the model in a high-level inference class that simplifies interaction.
2. Enabling Model Components for Fine-Tuning
When fine-tuning SAM 2 for image segmentation, the three essential components that can be trained are:
predictor.model.image_encoder
predictor.model.sam_prompt_encoder
predictor.model.sam_mask_decoder
Each of these modules can be selectively enabled for training based on your configuration and GPU capacity.
These components are implemented in PyTorch and can be selectively enabled for training. To fine-tune any of them, you need to set the module to training mode using .train(True) and ensure all parameters have requires_grad = True. For example:
predictor.model.sam_mask_decoder.train(True)
for p in predictor.model.sam_mask_decoder.parameters():
p.requires_grad = True
⚠️ Note: Be sure to comment out any @torch.no_grad() or @torch.inference_mode() decorators in the source code — particularly in the ./sam2 folder (sam2_image_predictor.py) of the repository. These decorators are designed to speed up inference by disabling gradient tracking and certain computation paths, but they will prevent training from working correctly.
3. Defining the Loss Function
To compute the difference between predicted masks and ground-truth masks, we need a suitable loss function. A convenient option is to use the segmentation_models_pytorch (SMP) library, which provides ready-to-use implementations of popular segmentation loss functions such as DiceLoss, FocalLoss, or combinations thereof.
In my own experiments, I used Dice Loss, as it is well-suited for segmentation tasks with imbalanced foreground and background pixels—a common scenario in medical imaging. However, depending on your dataset and goals, you may want to experiment with other loss functions like Binary Cross-Entropy, Focal Loss, or custom hybrids.
4. Selecting the Optimizer
Once the model and loss function are defined, the next step is to select an optimizer that will update the model’s parameters during training. In most PyTorch-based workflows, popular choices include SGD, Adam, and AdamW.
For my experiments, I used AdamW, which is a variant of the Adam optimizer with decoupled weight decay. It often works well in computer vision tasks and provides better generalization, especially when fine-tuning large pretrained models like SAM 2.
In my fine-tuning setup, I assigned different learning rates and weight decay values to individual components of the SAM 2 model. Specifically, I used a lower learning rate (1e-6) for the image encoder, since it is a large and sensitive component pretrained on diverse data. For the prompt encoder and the mask decoder, I used a slightly higher learning rate (5e-6), which allowed them to adapt more quickly to the target task. For all components, I applied a weight decay of 1e-4 to encourage regularization and improve generalization. This configuration proved effective in practice and led to stable training across multiple datasets.
5. Implementing the Training Loop
Once all components are prepared—model, optimizer, and loss function—we can implement the training loop:
During each iteration we first perform a forward pass using sam2_forward_pass(...) to obtain predicted masks. Both the predictions and ground-truth masks are then cast to float32, ensuring they are compatible for loss computation.
The loss is computed using the selected loss function (e.g., DiceLoss), and we then proceed with the standard PyTorch optimization routine: we reset gradients with optimizer.zero_grad(), perform backpropagation via loss_value.backward(), and update the model parameters using optimizer.step().
This training step is typically wrapped inside an epoch loop and may be extended with gradient accumulation, learning rate scheduling, or mixed-precision training as needed.
6. Writing the SAM 2 Forward Pass
Now lets dive into the forward pass implementation.
⚠️ Note: Be sure to comment out any @torch.no_grad() or @torch.inference_mode() decorators in the source code — particularly in the ./sam2 folder (sam2_image_predictor.py) of the repository. These decorators are designed to speed up inference by disabling gradient tracking and certain computation paths, but they will prevent training from working correctly.
First, we pass the input image batch through the SAM 2 image encoder. This step extracts high-level visual features from each image, which will later be combined with prompt embeddings to guide the segmentation process.
predictor.set_image_batch(images_list)
The images_list is expected to be a list of NumPy arrays, where each image has shape [H, W, C] (Height, Width, Channels) and is typically of type float32. The list itself emulates the batch dimension, allowing multiple images to be processed together.
Next, we prepare the prompt input — in this case, bounding boxes:
The variable bbox_coords contains the box coordinates in unnormalized format [x1, y1, x2, y2], where the values are in pixel units relative to the original input image size. These coordinates will be normalized internally by the model before being passed to the prompt encoder.
The prepared box coordinates are passed into the prompt encoder to obtain both sparse and dense embeddings:
Finally, the predicted masks are upsampled to the desired resolution (e.g. 512×512) and passed through a sigmoid activation to obtain per-pixel probabilities:
Since the model is configured with multimask_output=True, the mask decoder produces three candidate masks for each image. For fine-tuning, we only use the first output mask (index 0), which is usually the most relevant. This is done by slicing with preds[:, 0], reducing the shape from [B, N, H, W] to [B, H, W], where N is the number of masks per image. Applying torch.sigmoid then converts the raw logits into probability values.
Domain-Specific Video Segmentation with SAM 2 and Box Prompts
Alright, now that we’ve covered the essential components of fine-tuning SAM 2 for static images, let’s dive into video segmentation. Fortunately, many of the building blocks from the previous chapter — such as the loss function and optimizer — remain applicable. In this section, we’ll explore how to adapt the fine-tuning pipeline to work with video data using bounding box prompts.
For a practical introduction to how SAM 2 can be applied to video data, the official SAM 2 GitHub repository also includes a ready-to-run notebook for video segmentation. The video_predictor_example.ipynb demonstrates how to process a sequence of frames, apply prompts, and generate segmentation masks consistently across time. It’s a great starting point for understanding how SAM 2 handles video inputs and temporal context.
Similarly to the image-based setup, we need to go through several key steps: loading the same pretrained checkpoint used by the video predictor, enabling the desired model components for training, and defining a forward pass tailored for video inputs. Each of these steps builds upon the foundations we covered earlier, but with adjustments to handle sequential data and temporal dynamics.
⚠️ Note: In my own experiments, I fine-tuned SAM 2 for video segmentation using a custom approach tailored to my specific dataset. The recommendations in this section are based on what worked best for me in practice. I was working with sparsely annotated video sequences, where only a few frames had ground-truth masks available. To address this, I created training sequences of variable length — typically between 1 and 4 frames — and computed the loss only on the final frame of each sequence. This setup allowed the model to learn prompt propagation over time, while making the most out of limited annotations. In my experience, this approach led to more stable training and better generalization than using fixed-length sequences or computing loss on all frames.
1. Loading the Pretrained SAM 2 Checkpoint for Video
To begin fine-tuning SAM 2 for video segmentation, we first load the pretrained model in video mode using the build_sam2_video_predictor function. This function initializes the model with support for sequential frame processing and enables video-specific features such as temporal embeddings.
2. Trainable Modules in SAM 2 for Video Segmentation
When fine-tuning SAM 2 for video segmentation, the model includes several additional components specifically designed to handle temporal information. The following modules can be selectively enabled for training:
predictor.image_encoder – extracts visual features from each frame (same as in the image version),
predictor.sam_prompt_encoder – encodes prompts such as boxes or points,
predictor.sam_mask_decoder –generates segmentation masks from combined image features, prompt embeddings, and temporal memory,
predictor.memory_encoder – encodes past frame information to provide temporal context,
predictor.memory_attention – applies attention over temporal memory to support consistent object tracking,
predictor.obj_ptr_proj – projects memory features for object pointer modeling,
predictor.obj_ptr_tpos_proj – encodes temporal positional embeddings for object-level temporal reasoning.
These components work together to enable temporally consistent predictions across video frames. Since the model is based on PyTorch, fine-tuning any of these parts requires setting them to training mode using .train(True) and ensuring their parameters have requires_grad = True. This allows gradients to flow and weights to update during backpropagation:
predictor.memory_encoder.train(True)
for p in predictor.memory_encoder.parameters():
p.requires_grad = True
⚠️ Note: Be sure to comment out any @torch.no_grad() or @torch.inference_mode() decorators in the source code — particularly in the ./sam2 folder (sam2_video_predictor.py) of the repository. These decorators are designed to speed up inference by disabling gradient tracking and certain computation paths, but they will prevent training from working correctly.
3. Forward Pass for Video Segmentation with SAM 2
The video forward pass in SAM 2 requires more preparation than static image inference, as it handles multiple frames, memory management, and prompt propagation across time. The process is encapsulated in two functions: create_inference_state(...) and sam2_forward_pass(...).
Understanding and Customizing init_state()
Before implementing the forward pass, I highly recommend taking time to understand how the SAM2VideoPredictor works internally — especially the init_state() function. This method is responsible for creating the inference state, a central structure that stores everything SAM 2 needs to track and segment objects across video frames.
For training purposes, you’ll likely need to adapt this logic — especially to:
load frames and annotations from tensors or memory instead of a video path,
work with variable-length sequences, not full videos,
and adjust the input resolution (image_size) to match your training pipeline.
In my case, I implemented a simplified version of init_state() that accepts a preloaded batch of frames (from sequence_data) and integrates seamlessly with my training loop. This gave me full control over how sequences are formed, annotated, and processed during fine-tuning.
⚠️ Code Modification In order to get fine-tuning working correctly, I also had to modify line 794 in SAM2VideoPredictor. Originally, the code assumes that object_score_logits is always present:
However, during training with custom data or partial inputs, this key may be missing. To prevent errors and ensure the forward pass still works, I replaced it with a safe fallback:
This creates a dummy tensor when the score logits are not available, allowing the training process to proceed without crashing.
Putting It All Together: The Forward Pass for Video
Before running the forward pass, we first initialize a fresh inference state using our custom create_inference_state(...) function — a reimplementation of SAM 2’s original init_state(), adapted for training. This prepares all necessary structures for tracking, memory, and prompt inputs.
After creating the state, we call predictor.reset_state(...) to ensure the model starts with a clean internal memory. This is important to avoid any residual data from previous sequences during training or evaluation.
With the inference state initialized and reset, we can now run the forward pass for the current video sequence. We start by injecting the initial prompt — in this case, a bounding box — into the first frame (ann_frame_idx = 0) using predictor.add_new_points_or_box(...). This establishes the object we want to segment and track throughout the video.
If the sequence contains multiple frames, the model then propagates the object across the video using memory attention via predictor.propagate_in_video(...). This produces a set of predicted masks for each frame.
Finally, all masks are stacked and passed through a sigmoid to obtain per-pixel probabilities. The output preds has the shape [T, C, H, W], where T is the number of frames.
if inference_state["num_frames"] > 1:
for out_frame_idx, out_obj_ids, out_mask_logits in predictor.propagate_in_video(inference_state):
video_segments[out_frame_idx] = {
out_obj_id: out_mask_logits[i]
for i, out_obj_id in enumerate(out_obj_ids)
}
# Return video segments in shape: [T,C,H,W]
preds = torch.stack([torch.sigmoid(segment[ann_obj_id]) for segment in video_segments.values()]).to(device)
else:
# Return video segments in shape: [T,C,H,W]
preds = torch.sigmoid(out_mask_logits).to(device)
Final Notes
While implementing the forward pass, you may have noticed a potential limitation — all frames in the sequence are loaded into memory at once. This is not ideal for longer videos or real-time applications. Fortunately, there is an alternative implementation of SAM 2 designed for streaming input: segment-anything-2-real-time.
This real-time version of SAM 2 is optimized for sequential frame-by-frame processing and significantly reduces memory usage. The fine-tuned model you trained following this guide can be integrated into that pipeline, making it suitable for deployment in low-latency or resource-constrained environments.
I hope this walkthrough helped clarify how SAM2 can be fine-tuned for both image and video segmentation — and that it gave you a clearer path for applying it to your own project or research. If you have any questions, run into unexpected issues, or just want to share what you’re working on, feel free to reach out. I’ll be happy to help or discuss further. If you’re interested in a deeper dive into the methods and experiments behind this work — particularly in the context of medical video segmentation — feel free to check out my Master’s thesis, where many of these insights originated.
🚀 VMware Explore 2025 is here! If you haven’t checked the Content Catalog yet, grab a coffee, block your calendar, and don’t miss these carefully picked 10 sessions.
[CLOB1201LV] – William Lam If you ever dreamt of getting hands-on with VMware Cloud Foundation 9.0 but lack enterprise-grade hardware—this session is your ticket. Learn how to run a fully functional VCF lab with minimal resources, plus hardware tips and tricks to stretch every CPU cycle and gigabyte of RAM.
[INVB1300LV] – Frank Denneman & Johan van Amersfoort Designing infrastructure for AI is no joke. Frank and Johan share hard-earned insights on balancing model size, inference speed, GPU allocation, and backup pipelines. Expect practical strategies and an AI sizing tool demo—perfect for anyone serious about AI on-premises.
[INVB1070LV] – Frank Denneman & Shawn Kelly Learn how NVIDIA Dynamo supercharges LLM inference—up to 30× more tokens per GPU! If you’re integrating large AI models into your VMware Private AI Foundation stack, this session will open your eyes to what’s possible.
[CMTYQT1284LV] – Waldemar Pera In the cloud era, your secrets are gold. Waldemar shows how VCF and vSphere Kubernetes Service work together to lock down your data, manage encryption keys, and protect Kubernetes secrets holistically.
[CMTYQT1285LV] – Waldemar Pera Continue the journey from Part 1—this session gets hands-on with Thales CipherTrust Data Security Platform and shows how to apply airtight data governance across your hybrid cloud.
[CLOB1028LV] – Duncan Epping Ready for a storage revolution? Duncan walks you through the future of multitenant storage, S3 integration, and automated ransomware recovery—straight from the R&D lab. Storage and DR pros, mark this one with five stars!
[CLOB1067LV] – Duncan Epping & John Nicholson This one is for true storage geeks. Dive into how the new vSAN Express Storage Architecture squeezes out max NVMe performance, inline dedupe, and insane latency improvements. You’ll want to rewrite your vSAN notes after this.
[INVB1158LV] – Shawn Kelly & Justin Murray GPUs are gold in AI—learn how to virtualize and manage them right. From Multi-Instance GPUs to vMotion gotchas, this session packs benchmarks, demos, and best practices so you get the most out of your expensive silicon.
[CLOB1262LV] – Bob Plankers & Justin Murray This session blends tech, process, and people factors for securing AI workloads. If your org is building sovereign or regulated AI solutions, this talk will sharpen your strategy.
[CLOB1261LV] – Bob Plankers Stay ahead of security and compliance changes in VCF 9.0—features, deprecations, and future directions. Bob makes security updates practical and clear, so you stay audit-ready.
[CMTYQT1227LV] – Me & Eva Micankova And here’s my shameless plug: join us to see how we built an AI-ready homelab for fine-tuning cutting-edge segmentation models like SAM2. From setup tips to a real use case on polyp segmentation in colonoscopy videos—this is AI tinkering at its finest, done at home!
🔗 Don’t Miss Out – See You There!
I hope this shortlist sparks your excitement and helps you plan your VMware Explore 2025 days wisely. Got your own must-watch sessions? See you in Vegas!
At VMware Explore EU 2024, the session “AI Without GPUs: Using Your Existing CPU Resources to Run AI Workloads” showcased innovative approaches to AI and machine learning using CPUs. Presented by Earl Ruby from Broadcom and Keith Bradley from Nature Fresh Farms, this session emphasized the potential of leveraging Intel Xeon CPUs with Advanced Matrix Extensions (AMX) to run AI workloads efficiently without the need for GPUs.
Key Highlights:
Introduction to AMX:
AMX (Advanced Matrix Extensions), available in Intel’s Sapphire Rapids processors, enables high-performance matrix computations directly on CPUs, making them more capable of handling AI/ML tasks traditionally reserved for GPUs.
Why Use CPUs for AI?:
Cost Efficiency: Lower operating costs compared to GPUs.
Energy Efficiency: Ideal for environments where power consumption is a concern.
Sufficient Performance for Specific Use Cases: CPUs can efficiently handle tasks like inferencing and batch-processing ML workloads with models under 15-20 billion parameters.
Software Stack:
OpenVINO Toolkit: Optimizes AI/ML workloads on CPUs by compressing neural networks, improving inference performance with minimal accuracy loss.
Intel oneAPI: Provides a unified software environment for both CPU and GPU workloads.
Real-World Application:
Nature Fresh Farms: Demonstrated how AI-driven automation using CPUs effectively manages complex agricultural processes, including plant lifecycle control in greenhouses.
When to Choose CPUs Over GPUs:
Inferencing and Batch Processing: When real-time responses are not critical.
Sustainability Goals: Lower power consumption makes CPUs a viable option.
Cost-Conscious Environments: For scenarios where reducing operational costs is a priority.
At VMware Explore EU 2024, the session “Unlocking Your Data with VMware by Broadcom and NVIDIA — RAG Deep Dive” delivered fascinating insights into the power of Retrieval Augmented Generation (RAG). Led by Frank Denneman and Shawn Kelly, this session explored how combining large language models (LLMs) with proprietary organizational data can revolutionize data utilization in enterprises.
What is RAG?
RAG combines the strengths of LLMs with a Vector Database to enhance AI applications by integrating them with an organization’s proprietary data. This synergy allows for more precise and context-aware responses, crucial for business-critical operations.
Why RAG Matters:
Enhanced Accuracy: Unlike traditional LLMs prone to “hallucinations” or inaccuracies, RAG provides validated, up-to-date answers by sourcing information directly from relevant databases.
Contextual Relevance: It seamlessly blends general knowledge from LLMs with specific proprietary data, delivering highly relevant insights.
Traceability and Transparency: RAG solutions can cite the documents used to generate responses, addressing one of the significant limitations of traditional LLMs.
How RAG Works:
Data Indexing: Proprietary data is pre-processed and stored in a vector database.
Question Processing: When a query is made, it is semantically embedded and matched against the vector database.
Answer Generation: The most relevant data is retrieved and used to generate a precise answer.
Integration with NVIDIA:
NVIDIA’s Inference Microservice (NIM) accelerates this process by optimizing LLMs for rapid inference, leveraging GPU-accelerated infrastructure to enhance throughput and reduce latency.
At VMware Explore EU 2024, the session “Demystifying DPUs and GPUs in VMware Cloud Foundation” provided deep insights into how these advanced technologies are transforming modern data centers. Presented by Dave Morera and Peter Flecha, the session highlighted the integration and benefits of Data Processing Units (DPUs) and Graphics Processing Units (GPUs) in VMware Cloud Foundation (VCF).
Key Highlights:
Understanding DPUs:
Offloading and Acceleration: DPUs enhance performance by offloading network and communication tasks from the CPU, allowing more efficient resource usage and better performance for data-heavy operations.
Enhanced Security: By isolating security tasks, DPUs contribute to a stronger zero-trust security model, essential for protecting modern cloud environments.
Dual DPU Support: This feature offers high availability and increased network offload capacity, simplifying infrastructure management and boosting resilience.
Leveraging GPUs:
Accelerated AI and ML Workloads: GPUs in VMware environments significantly speed up data-intensive tasks like AI model training and inference.
Optimized Resource Utilization: VMware’s vSphere enables efficient GPU resource sharing through virtual GPU (vGPU) profiles, accommodating various workloads, including graphics, compute, and machine learning.
Distributed Services Engine:
This engine simplifies infrastructure management and enhances performance by integrating DPU-based services, creating a more secure and efficient data center architecture.
When planning to deploy a chatbot or simple Retrieval-Augmentation-Generation (RAG) pipeline on VMware Private AI Foundation with NVIDIA (PAIF-N) [1], you may have questions about sizing (capacity) and performance based on your existing GPU resources or potential future GPU acquisitions. For […]